Wer heute eine Empfehlung sucht, ein Produkt vergleicht oder eine Branchenfrage klärt, beginnt diesen Vorgang zunehmend in einer KI-Anwendung. Allein ChatGPT verzeichnet laut Anbieterangaben rund 810 Millionen tägliche Nutze (Stand März 2026). Eine Untersuchung von Similarweb für die USA zeigt, dass in der frühen Phase der Kaufentscheidung 35 Prozent der Befragten KI-Tools verwenden, während klassische Suchmaschinen auf 13,6 Prozent kommen (US-Daten, Jänner 2026). Bis eine User:in tatsächlich auf eine Website klickt, hat die KI-Antwort die Auswahl der genannten Marken bereits getroffen. Wer dort nicht vorkommt, ist nicht agent-ready, also faktisch unsichtbar geworden, obwohl die eigene Website weiterhin existiert.
Die Wirkung lässt sich auch in Zahlen sehen. Laut Cloudflare Radar (Stand April 2026) liefert Google noch 87,5 Prozent aller Such-Referrals an Websites, alle KI-Chatbots zusammen weniger als 0,3 Prozent. Wer diese Zahlen liest und die Entwicklung für überschaubar hält, übersieht zwei Punkte. Erstens entscheidet sich die Empfehlung schon vor dem Klick. Zweitens ist die Qualität dieser Klicks deutlich höher: Daten von Conductor (hier zitiert) zeigen, dass eine ChatGPT-Sitzung auf einer Website rund doppelt so lange dauert wie ein klassischer Google-Klick und dreifach besser konvertiert.
Damit ist die Frage für jeden Publisher: Wie sorgt man dafür, dass die eigene Website von KI-Systemen verstanden, korrekt zitiert und dabei gemäß der erwünschten Regeln genutzt wird?
Was bedeutet agent-ready?
Den Begriff „agent-ready“ hat Cloudflare im April 2026 mit dem öffentlichen Tool isitagentready.com populär gemacht. Es funktioniert ähnlich wie Google Lighthouse für die Performance einer Website: man trägt eine URL ein, das Tool prüft eine Reihe von Standards und gibt eine Bewertung mit konkreten Verbesserungsvorschlägen zurück. Geprüft werden vier Dimensionen.
- Auffindbarkeit umfasst die Frage, ob ein KI-System die Site überhaupt strukturiert erkunden kann. Eine sauber konfigurierte robots.txt, eine sitemap.xml und Link-Header nach RFC 8288 zählen dazu.
- Inhalt beschreibt, in welcher Form die Site ihre Texte bereitstellt. Hier kommen Markdown-Auslieferung über HTTP-Content-Negotiation und die Datei
/llms.txtins Spiel, eine Art Inhaltsverzeichnis für Sprachmodelle. - Bot-Zugriffskontrolle ist die wahrscheinlich folgenreichste Dimension für DACH-Unternehmen. Sie regelt, ob die Inhalte für klassische Indexierung, für Echtzeit-Verwendung in KI-Antworten oder für das Training von Modellen genutzt werden dürfen. Das geschieht über sogenannte Content Signals.
- Capabilities geht über das reine Lesen hinaus. Sie legen, ob – und wie – ein Agent mit der Site oder den Angeboten interagieren kann: Skill-Definitionen, API-Catalogs nach RFC 9727 und MCP-Server-Cards gehören in diesen Bereich.
Die Bestandsaufnahme von Cloudflare ist ernüchternd. In einer Untersuchung von 200000 Top-Domains haben zwar 78 Prozent eine robots.txt, aber nur vier Prozent deklarieren überhaupt eine AI-Nutzungspräferenz, knapp vier Prozent unterstützen Markdown-Negotiation und API-Catalogs finden sich auf weniger als 15 Sites im gesamten Datensatz. (Mehr dazu hier)
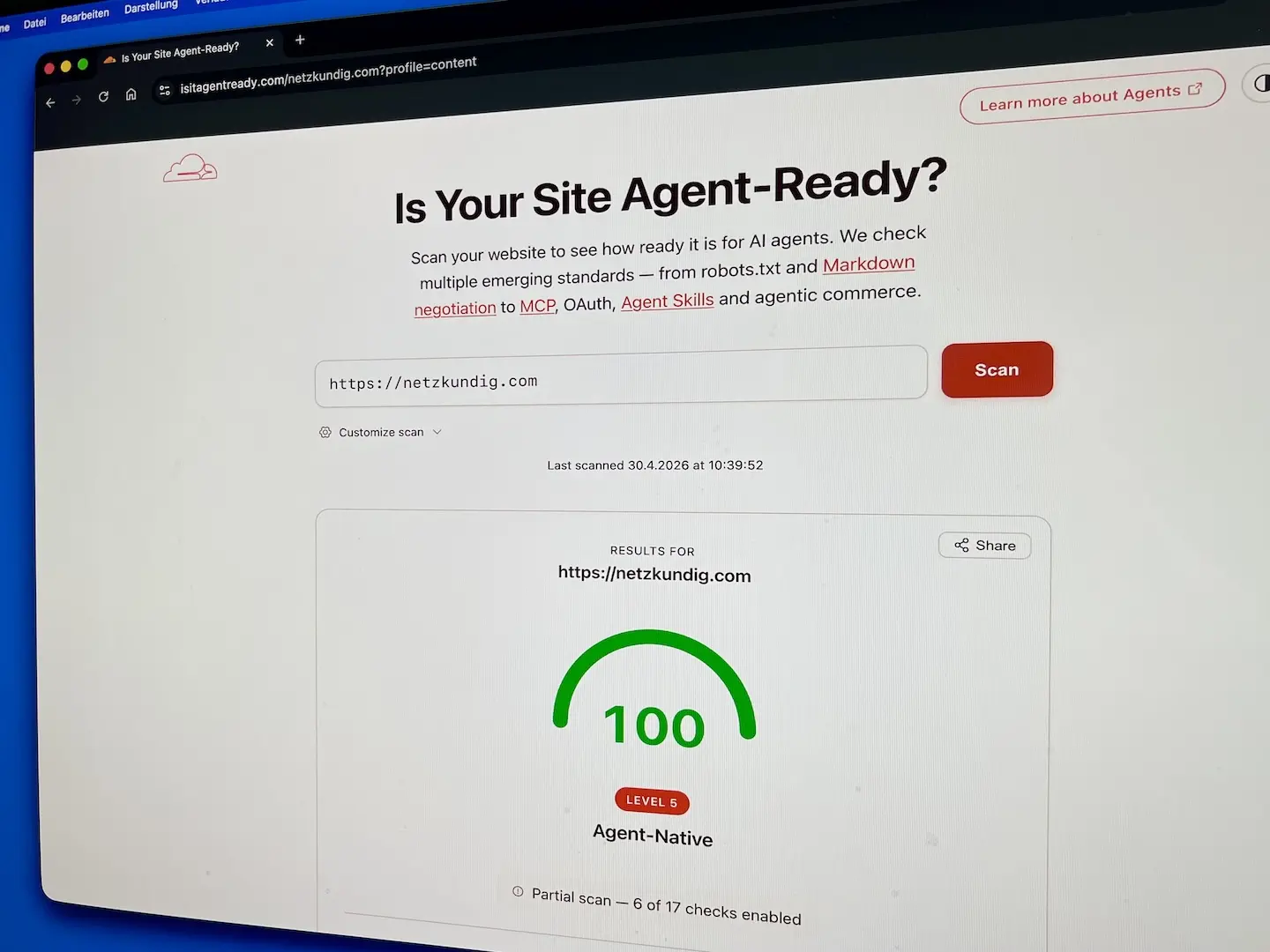
Wer die eigene Site testen möchte, kann das in ein bis zwei Minuten unter isitagentready.com tun. Die Wahrscheinlichkeit, dass das Ergebnis ernüchternd ausfällt, liegt aktuell übrigens bei über neunzig Prozent.
Warum sich eine Investition in Agent-Readiness jetzt lohnt
Drei Argumente sprechen dafür, Websites so bald wie möglich agent-ready zu machen.
- Sichtbarkeit in einer veränderten Discovery-Landschaft ist das offensichtlichste. Wenn ein KI-System bei einer Branchenfrage drei oder fünf Marken nennt, fällt der Erstkontakt auf diese Auswahl. Wer in der Antwort nicht erscheint, hat die Verhandlung um Aufmerksamkeit bereits verloren. Sites, die KI-Systemen sauber strukturierte Inhalte liefern, haben empirisch eine höhere Wahrscheinlichkeit, zitiert zu werden. Wer das früh adressiert, profitiert über eine längere Phase, weil die Erinnerungseffekte in Trainingsdaten und Indexen kumulativ wirken.
- Datensouveränität und rechtliche Klarheit sind besonders für regulierte Branchen, B2B-SaaS-Anbieter und Wissensplattformen relevant. Die alte
robots.txt-Logik kennt nur „darf crawlen“ oder „darf nicht crawlen“. Mit Content Signals lässt sich differenziert ausdrücken, dass Inhalte zwar in Suchergebnissen auftauchen, aber nicht für das Training von Modellen verwendet werden dürfen, oder dass Echtzeit-Verwendung in Antworten zulässig ist, Modelltraining hingegen nicht. Im EU-Kontext ist eine solche maschinenlesbare Aussage als ausdrücklicher Vorbehalt im Sinne von Artikel 4 der EU-Richtlinie 2019/790 zu verstehen. Damit liegt nicht mehr in der Verantwortung des Site-Betreibers, im Streitfall belegen zu müssen, dass keine Zustimmung erteilt wurde. Mehr dazu hier und im – Vorsicht, unnötig komplizierte Sprache! –Volltext der EU-Richtlinie 2019/790, Artikel 4. - Die aktuell niedrige Verbreitung von Agent Readiness: Wer früh in einem Feld aktiv wird, in dem nur ein einstelliger Prozentsatz der untersuchten Sites die einschlägigen Standards umsetzt, kann sich eine technische Pole-Position verschaffen und davon profitieren.
Die aktuelle Lage im WordPress-Ökosystem
WordPress ist mit einem Marktanteil von rund 43 Prozent (Stand April 2026) noch immer das verbreitetste CMS weltweit. Bei der Agent-Readiness hinkt das Plugin-Ökosystem aber noch hinterher. Aktuell sind drei Lösungswege erkennbar.
Cloudflare bietet mit „Markdown for Agents“ eine Edge-Lösung an. Sie wird per Toggle im Cloudflare-Dashboard aktiviert und konvertiert auf Anforderung HTML in Markdown. Für viele Sites ist das ein vernünftiger Mindeststandard, weil keine Anpassung am Origin (der WordPress-installation) nötig ist. Die Konvertierung arbeitet allerdings generisch und schließt das gesamte HTML einschließlich Navigation, Footer, Sidebar und Cookie-Banner mit ein. Außerdem setzt Cloudflare bei jeder konvertierten Antwort den Content-Signal-Header ai-train=yes, search=yes, ai-input=yes, also die maximal offene Voreinstellung. Wer Datensouveränität ernst meint, möchte das granular und individuell steuern.
Joost de Valk, bekannt als Gründer von Yoast SEO, hat mit „Markdown Alternate“ ein erstes Plugin veröffentlicht. Es operiert im WordPress-Core, hat damit Zugriff auf das volle Post-Objekt und liefert ein deutlich reicheres Frontmatter mit Autor, Datum, Kategorien und Tags. Das ist substantiell besser als die generische Edge-Lösung, deckt aber nur den Aspekt der Markdown-Auslieferung ab. Content Signals, llms.txt, Well-Known-Endpoints und Link-Header bleiben offen.
Daneben existieren mehrere kleinere Plugins, die jeweils Teilaspekte abdecken. „Markdown for AI Agents“ und „Serve Markdown“ auf wordpress.org sowie verschiedene GitHub-Projekte konzentrieren sich ebenfalls auf die Markdown-Variante. Ein kommerzielles Angebot mit Lizenzmodell ergänzt das Spektrum. Was alle gemeinsam haben: Sie lösen je einen Ausschnitt der Agent-Readiness-Matrix, kein einzelnes Plugin deckt das gesamte Bild ab.
Das ist eine unbefriedigende Situation. Es bräuchte ein Werkzeug, das alle vier Dimensionen aus dem isitagentready.com-Test in einer einzigen, durchdachten Lösung zusammenführt.
Was eine vollständige Lösung können muss
Aus den Anforderungen der vier Prüfdimensionen ergibt sich eine konkrete Checkliste. Ich nutze sie auch als Audit-Raster, wenn ich die Agent-Readiness einer bestehenden Site untersuche.
Eine vollständige Lösung sollte folgende Punkte abdecken:
- Markdown-Auslieferung über drei Triggerpfade, also über den
Accept-Header, über eine.md-URL-Variante und optional über einen Query-Parameter. - Sie sollte den Inhalt sauber vom Theme-Drumherum trennen, also ausschließlich den Hauptinhalt eines Beitrags konvertieren.
- Sie sollte ein WordPress-typisches, reichhaltiges Frontmatter mit Titel, Beschreibung, Autor, Datum, Kategorien, Tags, Beitragsbild und Sprache liefern.
- Sie sollte einzelnen Blöcken im Editor erlauben, aus der Markdown-Variante ausgenommen zu werden, damit Werbeflächen, Newsletter-Aufrufe oder Boxen mit verwandten Beiträgen für Menschen sichtbar bleiben, in der Agenten-Variante aber nicht erscheinen.
- Sie sollte einen Content-Signal-Header bei jeder Antwort setzen und parallel die robots.txt um eine konsistente Policy ergänzen.
- Sie sollte eine
/llms.txtals Inhaltsverzeichnis für Sprachmodelle generieren und optional eine ausführlichere/llms-full.txt. - Sie sollte die Endpunkte unter
/.well-known/bereitstellen, die das isitagentready-Tool prüft, also api-catalog, agent-skills, mcp.json und ai.txt. - Sie sollte Link-Header nach RFC 8288 setzen und in jedes HTML-Dokument einen
<link rel="alternate" type="text/markdown">einfügen. - Schließlich sollte sie ein Diagnose-Werkzeug enthalten, das die eigenen Konfigurationen prüft und das Ergebnis nachvollziehbar macht.
Diese Liste ist umfangreich, aber sie deckt den Stand der Standards Mitte 2026 ab. Wer sie ernst nimmt, muss zwangsläufig ein eigenständiges Plugin bauen, weil keines der bestehenden die volle Bandbreite anbietet.
Fazit: ein eigenes Plugin muss her
Aus diesem Grund entwickle derzeit ein WordPress-Plugin, das alle Punkte der Checkliste in einer modularen Architektur zusammenführt. Es besteht aus Modulen für alle Bestandteile der Ai-Readiness, die einzeln aktiviert oder deaktiviert werden können. Jedes kommt mit eigenen Einstellungen und einer eigenen Logik. Ein zentrales Diagnose-Tab ähnlich der Cloudflare-Logik prüft die eigene Site und zeigt, welche Bausteine richtig greifen und welche noch nachgezogen werden müssen.
Das markanteste Unterscheidungsmerkmal gegenüber den bestehenden Plugins ist die Steuerung des Markdowns auf Block-Ebene. Für jeden einzelnen Content-Block lässt sich über die erweiterten Einstellungen festlegen, ob er in der Markdown-Variante erscheinen soll. Bei Container-Blöcken wie Group, Columns oder Cover wirkt diese Markierung auf den gesamten enthaltenen Sub-Tree. Damit ist Markdown-Rendering nicht mehr generisch und willkürlich wie in der Edge-Lösung von Cloudflare. Was an Agenten geht, ist eine bewusst kuratierte Auswahl.
Ein zweites markantes Unterscheidungsmerkmal ist die durchgehende Mehrsprachigkeit. Die Frontmatter-Generierung erkennt Polylang und WPML automatisch, der Cache wird pro Sprachversion getrennt geführt, die Settings-Oberfläche und alle Hinweise sind übersetzt verfügbar. Für DACH-Sites mit Zweitsprache Englisch ist das in der Praxis wichtig, weil sich sonst sprachbezogene Eigenheiten in der Markdown-Variante als kleine, aber unangenehme Schönheitsfehler zeigen.
Das Plugin folgt einem Filter-First-Design. Jede Ausgabe und jede Entscheidung läuft durch einen WordPress-Filter, sodass sich Theme- und Branchenspezifika ohne Eingriff in den Plugin-Kern anpassen lassen. Wer eine besondere Frontmatter-Zeile braucht, ein Theme mit ungewöhnlichen Wrapper-Strukturen betreibt oder bestimmte Inhalte nach eigenen Regeln aus der Markdown-Variante ausschließen möchte, kann das über eigene Filter-Hooks lösen.
Status Ende April 2026: Testphase
Das Plugin läuft seit Mitte April 2026 im Testbetrieb auf mehreren Sites, darunter auf netzkundig.com selbst. Die Ergebnisse im isitagentready-Test liegen je nach Konfiguration zwischen achtzig und neunzig Prozent. Die einzelnen Module wurden in den letzten Wochen mehrfach gegen reale Theme- und Plugin-Kombinationen getestet, die in der Praxis erfahrungsgemäß für überraschende Effekte sorgen, beispielsweise Yoast SEO mit dynamischen Breadcrumbs, GenerateBlocks-Query-Loops und ACF-Blöcke.
In den kommenden Wochen werde ich das Toolkit weiteren ausgewählten Pilotkunden zur Verfügung stellen. Wer dazu gehören möchte, der kann sich gerne bei mir melden. Ebenfalls in Arbeit ist ein eigener Blogpost mit ausführlicher Architekturbeschreibung und Code-Beispielen.
Update: Das Plugin ist mittlerweile in einer ersten Version erhältlich. Mehr hier.
Wie ich jetzt schon helfen kann
Falls eine eigene WordPress-Site agent-ready werden soll, biete ich vier Bausteine an. Eine Bestandsaufnahme untersucht den aktuellen Stand mit dem isitagentready-Test und einer manuellen Analyse der Site-Struktur, der bestehenden robots.txt, der Cloudflare-Konfiguration und der Inhalte.
Eine Konfiguration richtet das Plugin und die ergänzenden Komponenten passend zur Site, ihrem Theme und ihren Branchenanforderungen ein. Eine Anpassung behandelt Sonderfälle, etwa bei stark individualisierten Themes, mehrsprachigen Setups oder besonderen Datenschutz-Anforderungen.
Eine Begleitung über mehrere Monate sorgt dafür, dass neu hinzukommende Standards wie Web Bot Auth, MCP-Server-Cards oder Agentic Commerce direkt nachgezogen werden, ohne dass die Site dafür jedes Mal neu untersucht werden muss.
Mein Schwerpunkt liegt auf Enterprise-Sites mit Substanz: regulierte Branchen, B2B-SaaS-Anbieter, Wissensplattformen, redaktionelle Sites mit langfristiger Inhaltsstrategie. Für diese Anwendungsfälle lohnt sich der Aufwand am ehesten, weil hier sowohl die Sichtbarkeit als auch die Datensouveränität geschäftsrelevant sind. Und weil hier auch minimale Verschiebungen beim Traffic einen grossen Effekt haben können, den es zu vermeiden gilt.
Zwei (einfache) nächste Schritte
Wer für die eigene Site einen schnellen Eindruck gewinnen möchte, kann zwei Dinge tun:
Der erste Schritt ist der Aufruf von isitagentready.com mit der eigenen Domain. Das Ergebnis liefert in zwei Minuten einen klaren Anhaltspunkt zur eigenen Position.
Der zweite Schritt ist ein Test der Markdown-Variante dieses Beitrags. Sie ist hier anzusehen und zeigt, wie eine sauber kuratierte Agent-Antwort aussieht. Wer eine eigene Site auf diesen Stand bringen möchte oder eine erste Analyse sucht, findet alle Kontaktdetails hier.
Eine Anmerkung zum Schluss: Markdown-Negotiation, Content Signals und die übrigen Standards sind Präferenzen, keine technischen Sperren. Sie sagen einem KI-Agent, was erwünscht ist und was nicht, sie können die tatsächliche Verwendung aber nicht im Sinne einer Firewall verhindern.
Wer das berücksichtigt, ordnet die Wirkung dieser Maßnahmen realistisch ein. Sie sind ein Hebel, kein Allheilmittel, und genau in dieser Rolle sind sie ihren Aufwand wert. Und sie sind wohl nie abgeschlossen, denn seit der allgemeinen Verfügbarkeit von generativer KI ändert sich die digitale Welt nochmals einen Tick schneller als wir es davor gewohnt waren.
